
谷歌推出全能扒谱AI:只要听一遍歌曲 钢琴小提琴的乐谱全有了
听一遍曲子,就能知道乐谱,还能马上演奏,而且还掌握“十八般乐器”,钢琴、小提琴、吉他等都不在话下。
这就不是人类音乐大师,而是谷歌推出的“多任务多音轨”音乐转音符模型MT3。
首先需要解释一下什么是多任务多音轨。
通常一首曲子是有多种乐器合奏而来,每个乐曲就是一个音轨,而多任务就是同时将不同音轨的乐谱同时还原出来。
还原后的多音轨听起来是这样的:
谷歌推出全能扒谱AI:只要听一遍歌曲,钢琴小提琴的乐谱全有了00:11听起来是不是很像原版演奏?事实上,谷歌MT3在还原多音轨乐谱这件事上,达到了SOTA的结果。
谷歌已将该论文投给ICLR 2022。
还原多音轨乐谱
相比与自动语音识别 (ASR) ,自动音乐转录 (AMT) 的难度要大得多,因为后者既要同时转录多个乐器,还要保留精细的音高和时间信息。
多音轨的自动音乐转录数据集更是“低资源”的。现有的开源音乐转录数据集一般只包含一到几百小时的音频,相比语音数据集动辄几千上万小时的市场,算是很少了。
先前的音乐转录主要集中在特定于任务的架构上,针对每个任务的各种乐器量身定制。
因此,作者受到低资源NLP任务迁移学习的启发,证明了通用Transformer模型可以执行多任务 AMT,并显著提高了低资源乐器的性能。
作者使用单一的通用Transformer架构T5,而且是T5“小”模型,其中包含大约6000万个参数。
该模型在编码器和解码器中使用了一系列标准的Transformer自注意力“块”。为了产生输出标记序列,该模型使用贪婪自回归解码:输入一个输入序列,将预测出下一个出现概率最高的输出标记附加到该序列中,并重复该过程直到结束 。
MT3使用梅尔频谱图作为输入。对于输出,作者构建了一个受MIDI规范启发的token词汇,称为“类MIDI”。
生成的乐谱通过开源软件FluidSynth渲染成音频。
此外,还要解决不同乐曲数据集不平衡和架构不同问题。
作者定义的通用输出token还允许模型同时在多个数据集的混合上进行训练,类似于用多语言翻译模型同时训练几种语言。
这种方法不仅简化了模型设计和训练,而且增加了模型可用训练数据的数量和多样性。
实际效果
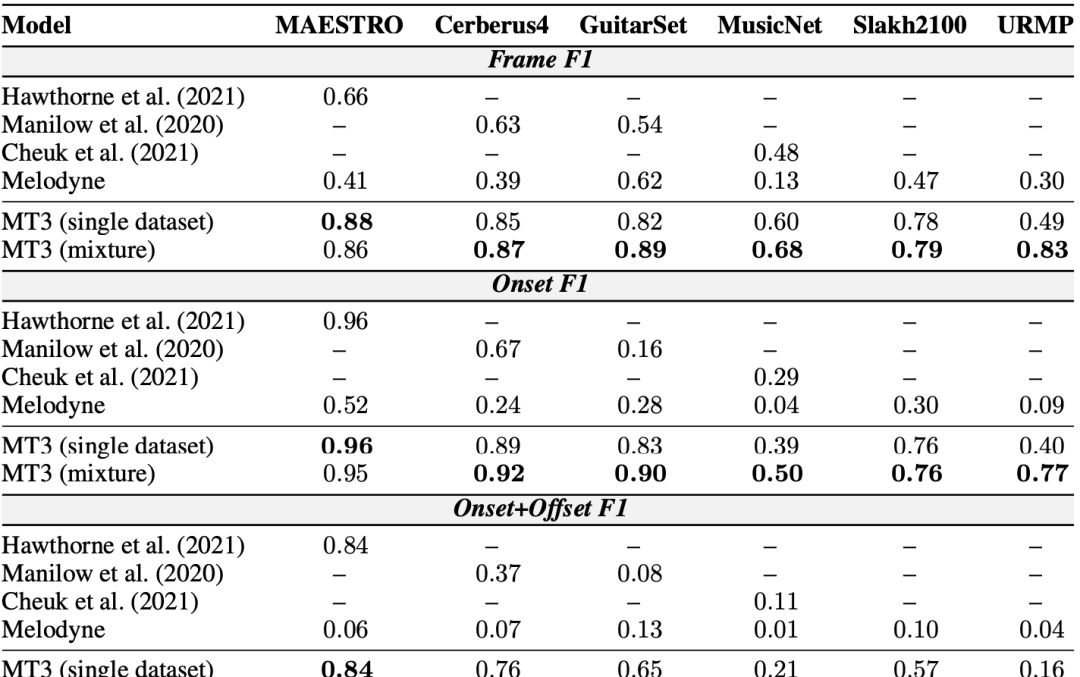
在所有指标和所有数据集上,MT3始终优于基线。
训练期间的数据集混合,相比单个数据集训练有很大的性能提升,特别是对于 GuitarSet、MusicNet 和 URMP 等“低资源”数据集。
最后再展示一段原音频,以及由MT3识别乐谱渲染的音频。大家可以感受一下区别:
原音频:
谷歌推出全能扒谱AI:只要听一遍歌曲,钢琴小提琴的乐谱全有了00:30MT3:
谷歌推出全能扒谱AI:只要听一遍歌曲,钢琴小提琴的乐谱全有了00:31最近,谷歌团队也放出了MT3的源代码,并在Hugging Face上放出了试玩Demo。
不过由于转换音频需要GPU资源,在Hugging Face上,建议各位将在Colab上运行Jupyter Notebook。





内容来自网友分享,若违规或者侵犯您的权益,请联系我们
所有跟帖: ( 主贴楼主有权删除不文明回复,拉黑不受欢迎的用户 )
进入内容页点击屏幕右上分享按钮
楼主前期社区热帖:
- 李自成兵败山海关,真因行军太慢吗?古代打仗军队一天能走多远 07/31/22
- 齐白石与黄宾虹的笔墨比较 07/31/22
- 司马氏主导的灭蜀、灭吴之役,为何总是演变为“二士争功”的悲剧 07/31/22
- 传统的中国美学是什么样的? 07/25/22
- 道光皇帝谋求大清朝中兴,他干了哪些事? 07/25/22
- 中国人深信的两份传世奇图 暗藏一个千年谎言? 07/25/22
- 16岁少年喝珍珠奶茶去世!学会这一招 关键时刻能救命 07/25/22
- 不运动也能增肌?打一针冬眠黑熊的血清就行 07/23/22
- 读《宋史》:王朴为何能留下美名? 07/09/22
- 明清广州府治南海、番禺二县说商榷 07/09/22
- 古人笔下的荷花,唯美了整个夏天 07/09/22
- 晚清龙骨的真相 07/01/22
- 大秦帝国灭六国实现大一统,为何仍保留了小小的卫国? 07/01/22
- 渐江的山水构图是怎么炼成的 07/01/22
- 泰国报告全球首例新冠“猫传人”病例 07/01/22
- 埋没的帅才,失意的英雄,三国赵云的人生际遇为何那么惨? 06/30/22
- 沈周:“好脾气”背后的人生哲学 06/30/22
- 历史“迷案”:汉献帝的“衣带诏”,究竟有无其事 06/30/22
- 闲得“五脊六兽”,都是哪些兽 06/30/22
- 乾隆养生丨晨起三百步,晚间一盆汤 06/30/22
>>>>查看更多楼主社区动态...