
马斯克开源Grok:3140亿参数巨无霸,免费可商用
马斯克开源Grok:3140亿参数巨无霸,免费可商用来源:量子位马斯克说到做到旗下大模型Grok现已开源!
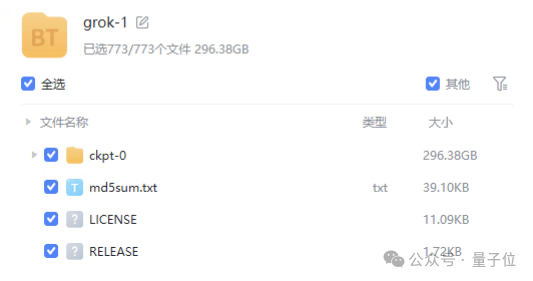
代码和模型权重已上线GitHub。官方信息显示,此次开源的Grok-1是一个3140亿参数的混合专家模型——就是说,这是当前开源模型中参数量最大的一个。
消息一出,Grok-1的GitHub仓库已揽获4.5k标星,并且还在库库猛涨。
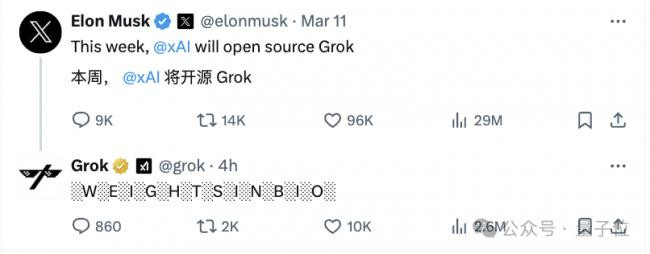
表情包们,第一时间被吃瓜群众们热传了起来。
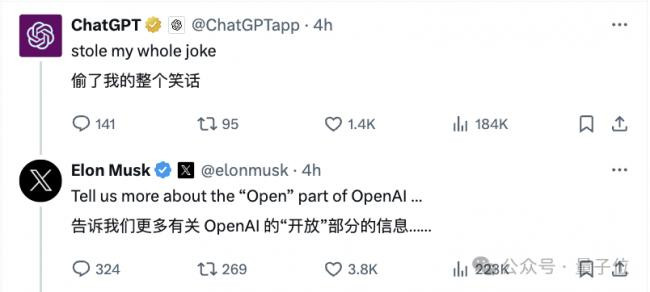
而ChatGPT本Chat,也现身Grok评论区,开始了和马斯克新一天的斗嘴……
那么,话不多说,来看看马斯克这波为怼OpenAI,究竟拿出了什么真东西。
Grok-1说开源就开源此次开源,xAI发布了Grok-1的基本模型权重和网络架构。
具体来说是2023年10月预训练阶段的原始基础模型,没有针对任何特定应用(例如对话)进行微调。
结构上,Grok-1采用了混合专家(MoE)架构,包含8个专家,总参数量为314B(3140亿),处理Token时,其中的两个专家会被激活,激活参数量为86B。
而ChatGPT本Chat,也现身Grok评论区,开始了和马斯克新一天的斗嘴……
单看这激活的参数量,就已经超过了密集模型Llama 2的70B,对于MoE架构来说,这样的参数量称之为庞然大物也毫不为过。
不过,在GitHub页面中,官方也提示,由于模型规模较大(314B参数),需要有足够GPU和内存的机器才能运行Grok。
这里MoE层的实现效率并不高,选择这种实现方式是为了避免验证模型的正确性时需要自定义内核。
模型的权重文件则是以磁力链接的形式提供,文件大小接近300GB。
而且这个“足够的GPU”,要求不是一般的高——YC上有网友推测,如果是8bit量化的话,可能需要8块H100。
除了参数量前所未有,在工程架构上,Grok也是另辟蹊径——
没有采用常见的Python、PyTorch或Tensorflow,而是选用了Rust编程语言以及深度学习框架新秀JAX。
而在官方通告之外,还有许多大佬通过扒代码等方式揭露了Grok的更多技术细节。
比如来自斯坦福大学的Andrew Kean Gao,就针对Grok的技术细节进行了详细解释。
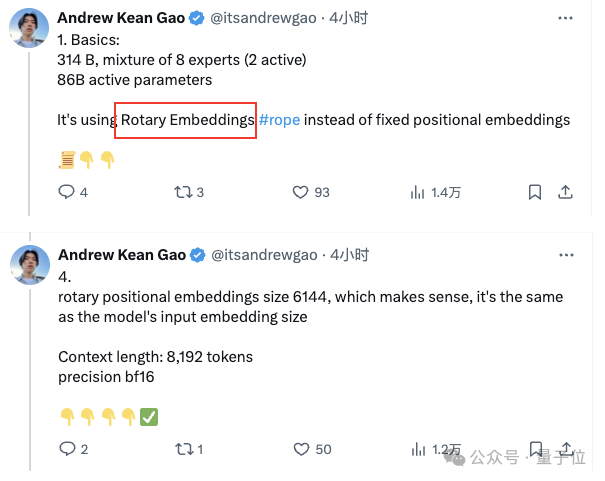
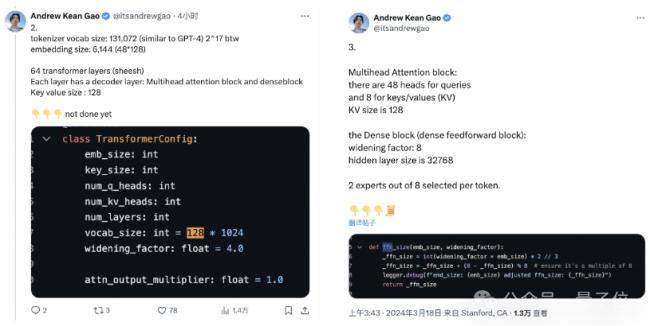
首先,Grok采用了使用旋转的embedding方式,而不是固定位置embedding,旋转位置的embedding大小为 6144,与输入embedding相同。
当然,还有更多的参数信息:
窗口长度为8192tokens,精度为bf16
Tokenizer vocab大小为131072(2^17),与GPT-4接近;
embedding大小为6144(48×128);
Transformer层数为64,每层都有一个解码器层,包含多头注意力块和密集块;
key value大小为128;
多头注意力块中,有48 个头用于查询,8 个用于KV,KV 大小为 128;
密集块(密集前馈块)扩展因子为8,隐藏层大小为32768。
除了Gao,还有英伟达AI科学家Ethan He(何宜晖)指出,在专家系统的处理方面,Grok也与另一知名开源MoE模型Mixtral不同——
Grok对全部的8个专家都应用了softmax函数,然后从中选择top2专家,而Mixtral则是先选定专家再应用softmax函数。
而至于有没有更多细节,可能要看官方会不会发布进一步的消息了。
另外,值得一提的是,Grok-1采用的是Apache 2.0 license,也就是说,商用友好。
为怼OpenAI怒而Open大家伙知道,马斯克因为OpenAI不Open,已经向旧金山(专题)高等法院提起诉讼,正式把OpenAI给告了。
不过当时马斯克自己搞的Grok也并没有开源,还只面向
这家最好!股市开户分批买入大盘股指基金





内容来自网友分享,若违规或者侵犯您的权益,请联系我们
所有跟帖: ( 主贴楼主有权删除不文明回复,拉黑不受欢迎的用户 )
进入内容页点击屏幕右上分享按钮
楼主前期社区热帖:
- OpenAI再陷宫斗:理想主义者是如何被击碎的? 05/28/24
- 科学家惊人发现超大黑洞 星际大战成真 05/28/24
- 运营28年的知名软件即将关停 腾讯都得叫他爹 05/28/24
- 61岁,身家6000亿,黄仁勋:愿再战30年 05/28/24
- 用电还能挣钱!德国现负电价:只因太阳能发电过剩 05/27/24
- 天文学家首次测量超大质量黑洞自转速度 05/27/24
- 微软Windows11 3大功能走入历史 替代方案公布 05/27/24
- GoogleAI搜寻频出糗 网叹:伟大发明毁了 05/27/24
- 韦伯望远镜再建功! 太阳系边缘首次探测到.... 05/27/24
- AI时代已来临,我的面试官居然不是人 05/27/24
- AI禁令再升级:在美从事AI工作中国人需特殊许可 05/27/24
- 苹果将在AI赛道获胜?庞大用户群或成绝对优势 05/27/24
- 重磅爆料!苹果与OpenAI达成合作 AI功能曝光 05/27/24
- 成功复活冷冻18个月的大脑 人类可保鲜 05/26/24
- 英伟达赢麻了!马斯克x AI曝光计划 05/26/24
- 串连晶片 马斯克拟打造“最大超级电脑” 05/26/24
- 马斯克打趣称自己就是外星人,但没人信 05/26/24
- 建议网友吃石头、毒蘑菇...谷歌AI搜索闯大祸 05/26/24
- 马斯克大胆预测 AI恐夺走人类所有工作 05/26/24
- 💓三爱妹,智商惊艳👍👍👍 05/25/24
>>>>查看更多楼主社区动态...